이번 글에서는 샤딩과 클러스터링, 레플리케이션을 비교해보고 그 차이점을 알아보도록 하겠습니다.
아래 사진은 가장 기본적인 DB 구조 입니다.

위 사진은 DB 서버와 디스크 역할을 하는 DB 스토리지가 한 구성으로 되있습니다.
그런데 이 구성과 같이 DB를 한 대만 운영 할 경우에 문제점은 DB 서버가 죽으면 관련된 서비스가 전체가 중단되게 됩니다.

이에 대한 가장 간단한 방안으로 DB 클러스터(Cluster) 가 있습니다. 위 사진과 같이 클러스터를 구성하는 것을 클러스터링(Clustering) 이라 합니다.
동일한 DB 서버를 두 대를 묶고 두 DB 서버를 Active-Active 상태로 운영하면, 하나의 DB 서버가 죽더라도 나머지 DB 서버가 살아있기 때문에 정상적으로 서비스가 가능해집니다. 또한 이전에는 하나의 서버가 부담하던 부하를 두 개의 DB가 나눠서 감당하므로 CPU, Memory 자원의 부하도 적어지게 됩니다.
단점으로는 DB 스토리지를 두 DB 서버가 공유하기 때문에 병목이 생길 수가 있다는 점과 이전보다 많은 비용이 투자되어야 한다는 점이 있습니다.

그 단점을 보완하기 위한 방안은 두 DB 서버 중 한 대를 Stand-by로 두는 것 입니다. 말 그대로 준비 상태로 두고 Active 상태의 DB 서버에 문제가 생겼을 때 Fail over를 통해 두 서버가 Active와 Stand-by의 상태를 상호 전환함으로써 장애를 대응 할 수 있습니다.
그리고 Active-Active 일 때의 단점이 었던 DB 스토리지 병목 현상이 해결되게 됩니다.
이 아키텍처 또한 단점이 있는데,
Fail over가 이뤄지는 수초~수분 간의 시간 동안에는 영업 손실이 필연적으로 발생하게 된다는 점,
결과적으로 DB 서버 두 대를 구비해야 하기 때문에 비용은 전과 동일하지만 효율은 이전 보다 약 1/2 정도 안 나온다는 점 입니다.
클러스터링의 설명을 보다 보면 DB 스토리지는 하나만 둬도 되는걸까? 라는 생각이 들 것입니다. 하나 뿐인 DB 스토리지에 문제가 생기면 데이터를 복구할 수 없게 되기 때문입니다.
그래서 나온 개념이 레플리케이션 (Replication) 입니다.
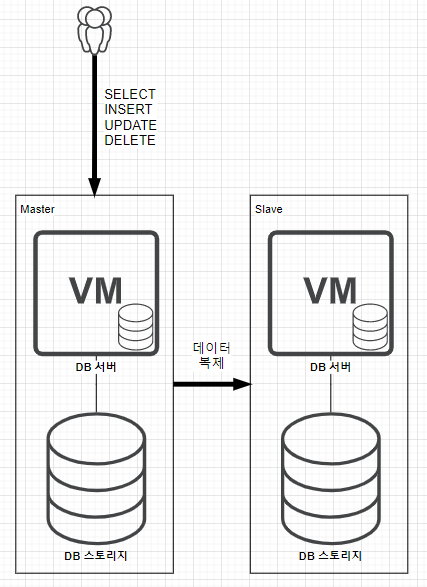
사용자는 마스터 DB 서버에 DML(SELECT/INSERT/UPDATE/DELETE) 작업을 하면 Master DB는 그 데이터를 Slave 쪽에 데이터 복제를 합니다.
이를 통해 DB 스토리지가 한 대여서 발생 할 수 있는 데이터 손실을 방지할 수 있습니다.
위 구성의 단점은 Slave인 DB 서버가 놀게 된다는 점 입니다.
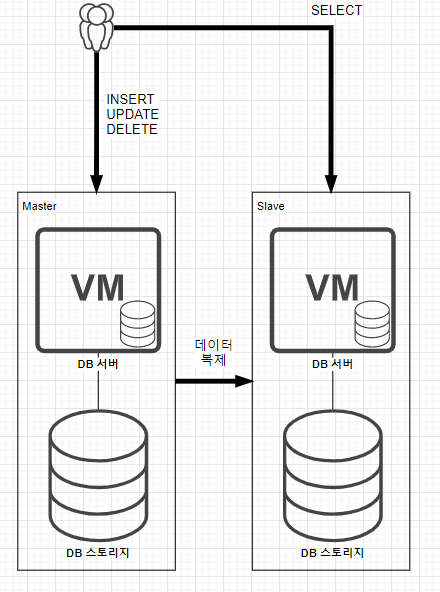
그래서 Master DB 서버에는 INSERT, UPDATE, DELETE 작업을 하고 Slave DB 서버에는 SELECT를 함으로써 양 DB 서버에 부하를 분산할 수 있습니다.
다만 아쉬운 점은 여전히 존재하는데, 만약에 테이블에 데이터 자체가 엄청나게 많다고 가정하겠습니다. 그러면 Slave DB 서버를 N 대로 늘려도 원하는 데이터를 테이블로 부터 찾는데 많은 시간이 소요될 것 입니다.
그 때 활용이 가능한 것이 샤딩(Sharding) 입니다.
샤딩은 테이블을 특정 기준으로 나눠서 저장 및 검색하는 것을 말합니다.
샤딩의 핵심은 Data를 어떻게 잘 분산 시켜 저장할 것인지, 그리고 어떻게 잘 읽을 것인지에 대한 결정 입니다.
어떻게 잘 분산 시켜 저장할지에 기준이 되는 것이 Shard Key 입니다.
대표적인 Shard Key 방식은 크게 세 가지가 있습니다..
첫 번째로 Hash Sharding 입니다.
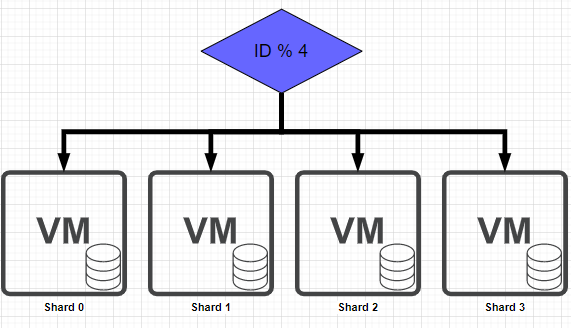
샤드의 수 만큼 Hash 함수를 사용 해서 나온 결과에 따라 DB 서버에 저장하는 방식으로 정말 구현이 간단하는 것이 장점 입니다.
단점은 확장성이 낮다는 것으로 DB 서버가 추가 될 경우 해쉬 함수가 변경되어야 하므로 기존에 저장되던 데이터의 정합성이 깨지게 됩니다.
이러한 확장성을 해결하기 위해 나온 것이 Dynamic Sharding 입니다.

로케이터 서비스는 테이블 형식의 데이터를 바탕으로 샤드를 결정해서 적절히 저장 하는 방식을 말합니다. 해쉬 샤딩과 달리 단순히 키만 추가해주면 되므로 확장 또한 쉽습니다.
단점으로는 로케이터 서비스가 단일 장애점이 되므로, 로케이터 서비스에 장애가 발생하면 나머지 샤드 또한 문제가 발생하게 됩니다.
세 번째는 Entity Group 입니다.
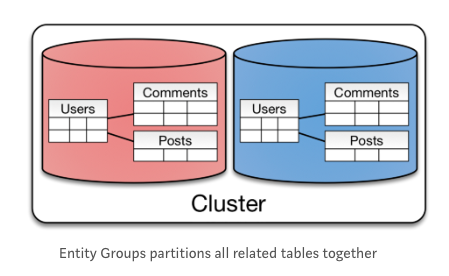
앞서 말씀 드린 두 샤딩 방식은 NoSQL 최적화 되어 있는 반면, 이 방식은 RDB와 잘 어울리는 방식 입니다.
엔티티 그룹은 연관성이 있는 엔티티를 한 샤드에 두는 방식 입니다. 같은 샤드에 있는 데이터를 조회할 때는 효과적이지만, 다른 샤드에 있는 데이터를 함께 조회할 때는 오히려 성능이 떨어지는 단점이 있습니다.
지금까지 클러스터링과 레플리케이션, 샤딩에 대하여 설명 해보았습니다.
각각의 기술의 특성과 장, 단점 그리고 현재 인프라, 아키텍처 환경을 고려하여 적재적소에 맞게 선택하여 도입하는 것이 가장 중요하다고 생각합니다.
지금까지 글을 읽어주셔서 감사합니다.
'Database' 카테고리의 다른 글
| 시나리오를 통해 Flyway 사용법 학습하기 (1) | 2021.10.05 |
|---|---|
| [H2] 원하는 이름으로 된 Non-In-Memory H2 서버 만들기 (0) | 2021.10.04 |
| 트랜잭션과 격리 레벨 그리고 Lock에 대하여 (2) | 2020.12.19 |
| [퍼온 글] MySql 원격 접속 방법 (0) | 2020.06.21 |
| [퍼온 글] 레디스 (0) | 2020.06.16 |

